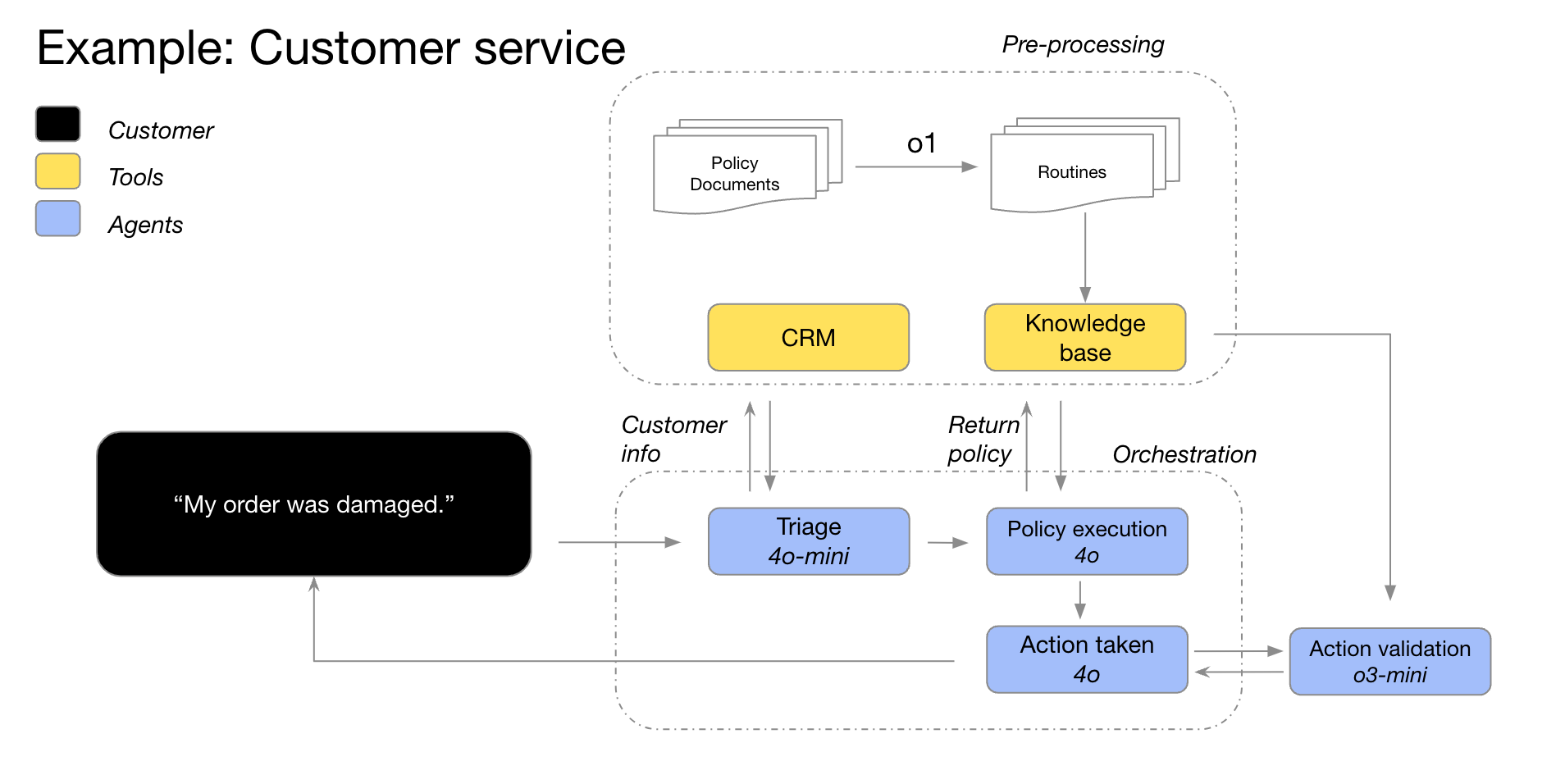
What are Reasoning Models?
- OpenAI o1-o3
- DeepSeek R1
- Google Gemini 2.0 Flash Thinking
- Mistral Pixtral Large
- Axai Gork 3
Understanding Reasoning Models
Reasoning Models are the most efficient models because they are more sophisticated than LLMs.
Reasoning models:
- Are trained on detailed reasoning (*chain of thought*)
- Use logical algorithms (*Prolog, * a French language)
- Manipulate *concepts* and not only language
OpenAI gives very specific examples in its guidebook best practices:
“To analyze the acquisition of a business, o1 examined dozens of company documents, such as contracts and leases, to detect delicate conditions that could affect the transaction. The model was responsible for reporting key terms and, in doing so, identified a crucial “change of control” provision in the footnotes: if the business was sold, it would have to repay a $75 million loan immediately. o1's extreme attention to detail allows our AI agents to support financial professionals by identifying mission-critical information.”
Endex, financial intelligence platform Artificial Intelligence
“We're automating risk and compliance reviews for millions of products online, including duped luxury jewelry, endangered species, and controlled substances. gpt-4o achieved 50% accuracy on our most challenging image classification tasks. o1 achieved an impressive 88% accuracy with no changes to our pipeline.”
SafetyKit, a risk management and compliance platform based on Artificial Intelligence
The costs of Reasoning Models
For the moment these models are slower, and above all much more expensive to operate:
- Gpt-4o mini: $0.6/1M tokens
- Gpt-4o: $10/1M tokens
- o1: $60/1M tokens
- o3-mini: $4.4/1M tokens
- o3: several tens of dollars for a single request
Why are there so many models?
Editors generally offer 3 models with different performances: small/medium/large.
- We are moving to 6 models, because they are updated: small1, small2, medium1, etc.
- We move on to 12 models with the arrival of reasoning models: small-reasoning 1, etc.
- And even more models with model specialization: mini-reasing-code, large-reasing-deepresearch, etc.
How to appropriate the subject of Reasoning Models?
- For the general public, the choice of model will certainly disappear very soon, in favor of a single single model (=GPT-5) which will decide the sub-model and the degree of effort himself, with the possibility for the user to configure his choices.
- For experiments, the question does not arise, in general classical models (Gpt-4o) are sufficient, or on the contrary o3 is obvious, and the question of cost of use is not yet a subject.
- In the industrialization phase, it is necessary to effectively optimize and choose the models to be used, both for reasons of cost, speed, and performance.